DeepSeek V4 Ollama is the cheat code I wish I had three months ago — a frontier-grade model running through Ollama, with zero local download and zero GPU bills.
Let me show you how I got it live in under five minutes and bolted it into every harness I use daily.
I've spent the last week running DeepSeek V4 Flash through Ollama as my daily driver and the results are honestly silly.
Free model. Free harness. Agent-grade output.
If that sounds too good to be true, stick with me — I'll walk you through exactly what's happening under the hood.
Why DeepSeek V4 Ollama is the Move Right Now
Most people hear "Ollama" and assume you need a meaty Mac or a bunch of GPUs to run anything decent.
That used to be true.
Then DeepSeek V4 Flash dropped as a cloud model inside Ollama and the rules changed overnight.
Here's the kicker — the model doesn't run on your machine. It runs on Ollama's servers. You just pipe requests through the Ollama CLI like normal.
So you get:
- Zero hardware requirements — no RAM ceiling, no GPU, no cooling-fan symphony
- Zero download time — no 70GB weights to pull
- Free tier with usage limits that are honestly generous
- The same
ollama runworkflow you already know
That's why DeepSeek V4 Ollama is the lead I'm telling everyone to chase first.
Step 1: Install or Update Ollama
You need the latest Ollama for V4 support — old versions won't see the cloud models.
Head to ollama.com and grab the install line. On Mac and Linux it's the standard curl one-liner you paste into terminal.
If you've already got Ollama, run the same install command — it'll update in place.
Don't skip this. I tried using a six-week-old build and the model name wouldn't resolve.
Step 2: Pull DeepSeek V4 Flash from the Cloud
Open the models page on ollama.com and search for DeepSeek V4 Flash.
Notice the little cloud icon — that's your tell that it's hosted, not local.
In your terminal, run:
ollama run deepseek-v4-flash
That's it.
No download bar. No "extracting layers" message.
It just opens a chat prompt and you start talking.
Want my exact terminal setup, the harness configs, and my live agent stack? Inside the AI Profit Boardroom, I've got a full free-AI-stack section with step-by-step videos showing the exact Ollama configs I'm running, plus weekly coaching calls where you can share your screen and I'll help you wire DeepSeek V4 into your own workflow. 3,000+ members already inside. → Get access here
Step 3: Talk to DeepSeek V4 Directly
The first thing I noticed — DeepSeek V4 thinks in Chinese and replies in English.
Sounds odd. Doesn't matter. Output is sharp.
Ask it anything in the terminal — code questions, summarisation, reasoning chains — it handles them cleanly.
But here's the honest bit.
Raw DeepSeek in the terminal is a good chatbot. That's it.
It can't browse the web. It can't run tools. It can't schedule tasks.
For that, you need a harness. And this is where it gets fun.
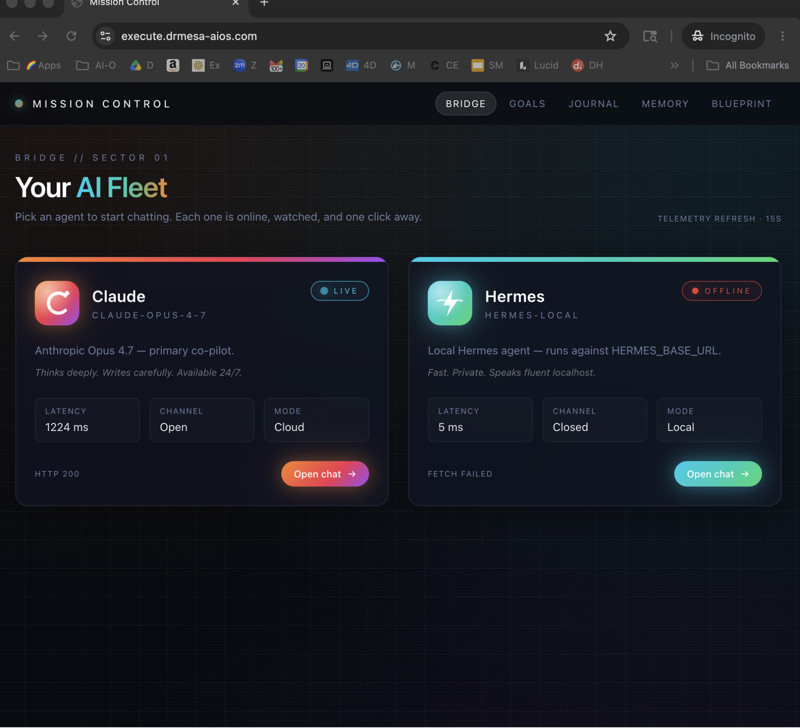
The Real Unlock: Multiple Harnesses, One Model
Open a new terminal tab with Cmd+T on Mac — and another, and another.
Now you've got DeepSeek V4 Flash piped into:
- Claude Code — for coding tasks where you want Claude's planning loop with DeepSeek's brain
- Codex (OpenAI's CLI) — built me a working ping pong game in one shot
- Open Code — quietly built a full blog post page locally
- OpenClaw — browser automation, runs as a local web UI on a gateway
- Hermes — scheduled agents that just work
- Ollama raw chat — the fallback for quick questions
All free. All running in parallel. All powered by the same DeepSeek V4 brain.
I had six tabs open at once last Tuesday and watched all of them grind through real work simultaneously.
OpenClaw + DeepSeek V4 = Browser Automation Magic
This is the combo that made me sit up.
I told OpenClaw "go speak to ChatGPT" — and it opened ChatGPT in my browser instantly and started typing.
Not a recording. Not a script.
Live browser control, driven by DeepSeek V4 thinking.
If you're new to OpenClaw, start with my OpenClaw AI SEO breakdown — that'll get you grounded before you bolt DeepSeek to it.
Hermes + DeepSeek V4 = Set-and-Forget Agents
Hermes is the harness for scheduled work.
I asked it to research the latest AI automation news daily and ship me a summary.
Took thirty seconds to set up. Runs forever.
The pairing with DeepSeek V4 is smooth — way smoother than the open-source models I was running through Hermes last month. If you've been using Hermes with Gemma 4, DeepSeek V4 is a noticeable step up in agent reliability.
Codex + DeepSeek V4 for Pure Coding
Codex is OpenAI's CLI but you can point it at any model — including DeepSeek V4 through Ollama.
I asked it to build a ping pong game.
Five minutes later I had a working browser game.
For raw coding tasks, this combo is hard to beat — and it's totally free.
The Insight Most People Miss
Here's the thing nobody talks about.
The harness matters more than the API.
DeepSeek V4 raw on chat.deepseek.com is fine. Solid model. Decent answers.
But it's not agentic. It can't do anything for you.
Wrap that exact same model in OpenClaw or Hermes and suddenly it's running your browser, scheduling your research, and shipping code.
The harness is what controls the API calls, the tool use, the loops, the retries.
The model is just the brain inside the body.
DeepSeek V4 Ollama gives you a frontier brain. The harnesses give you the body parts.
Stack them right and you're operating at a level that would have cost £200/month in API fees six months ago.
🔥 Want to skip the trial-and-error? Inside the AI Profit Boardroom I've recorded the exact harness setup, the Hermes scheduled-agent flow, and the OpenClaw browser automation builds — all running on free DeepSeek V4 Ollama. Plus weekly Q&A calls where I look at YOUR setup. 3,000+ members building right now. → Join here
Common Pitfalls When Setting Up DeepSeek V4 Ollama
A few things that tripped me up so they don't trip you up:
- Old Ollama version — update first, always
- Wrong model name — copy it directly from ollama.com, don't guess
- Trying to do agentic work in raw Ollama chat — won't work, that's what the harnesses are for
- Free tier limits — be aware they exist; for heavy workloads you may hit them
- Assuming local install — V4 Flash is cloud-only via Ollama right now
My Real Daily Workflow with DeepSeek V4 Ollama
Morning: Hermes runs my scheduled news research — I read the summary with coffee.
Mid-morning: OpenClaw handles browser tasks I'd normally fluff around with for an hour.
Afternoon: Claude Code or Codex pointed at DeepSeek V4 for coding sessions.
Evening: Open Code for blog page builds.
All same model. All same Ollama install. All free.
If you've been on the fence about the DeepSeek V4 tutorial setup, running it through Ollama is the lowest-friction entry point you'll find.
Related reading
- DeepSeek V4 Tutorial — the full model breakdown if you want background on V4
- OpenClaw AI SEO — primer on the OpenClaw harness before you bolt DeepSeek to it
- Ollama + Hermes — the scheduled-agent setup that pairs perfectly with V4 Flash
FAQ
Is DeepSeek V4 Ollama really free?
Yes — DeepSeek V4 Flash runs as a cloud model on Ollama's servers with a free tier. There are usage limits but for most users they're more than enough for daily agent work.
Do I need a GPU for DeepSeek V4 Ollama?
No. That's the whole point of the cloud model setup. Your machine just sends requests through the Ollama CLI — the actual inference happens on Ollama's hardware.
Can DeepSeek V4 Ollama work with Claude Code?
Yes. You point Claude Code at the local Ollama endpoint and it'll route through DeepSeek V4 Flash. Same for Codex, Open Code, OpenClaw and Hermes.
Why does DeepSeek V4 think in Chinese?
It's a Chinese-developed model and its internal reasoning chain often surfaces in Chinese before the English response. Doesn't affect output quality at all — answers come back in clear English.
What's better — DeepSeek V4 Ollama or the chat.deepseek.com web UI?
For chatting, they're similar. For agentic work, Ollama wins by a mile because you can wire it into harnesses like OpenClaw and Hermes that the web UI can't touch.
How does DeepSeek V4 Ollama compare to running Kimi K2.6 locally?
DeepSeek V4 Ollama needs zero hardware. Kimi K2.6 for agent swarms is brilliant but needs serious local resources or paid API. For most people, V4 Flash on Ollama is the easier win.
Get a FREE AI Course + Community + 1,000 AI Agents 👉 Join here
Video notes + links to the tools 👉 Boardroom
Learn how I make these videos 👉 aiprofitboardroom.com
DeepSeek V4 Ollama is the shortest path I've found to running a frontier model in your stack without a credit card or a graphics card — start there and the rest of the agent world opens up.