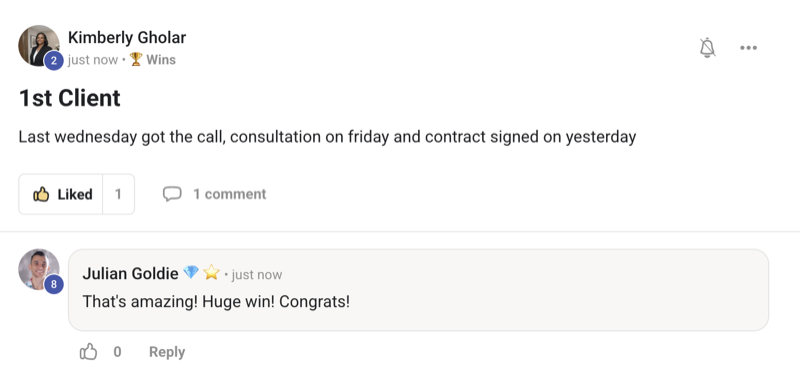
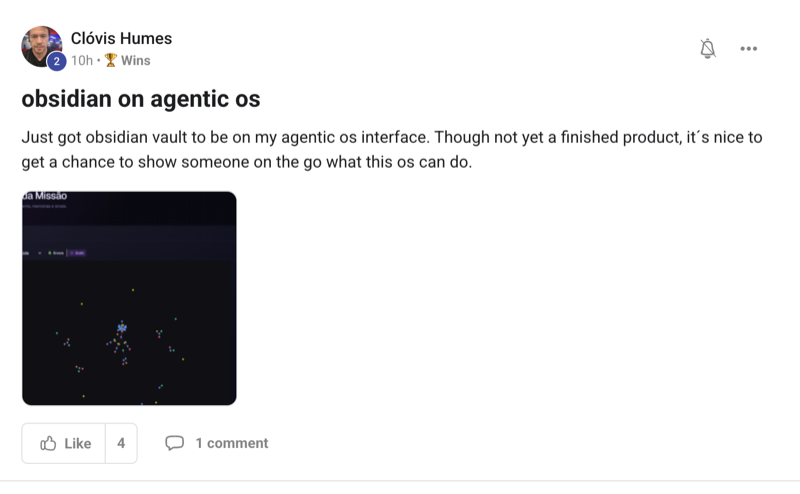
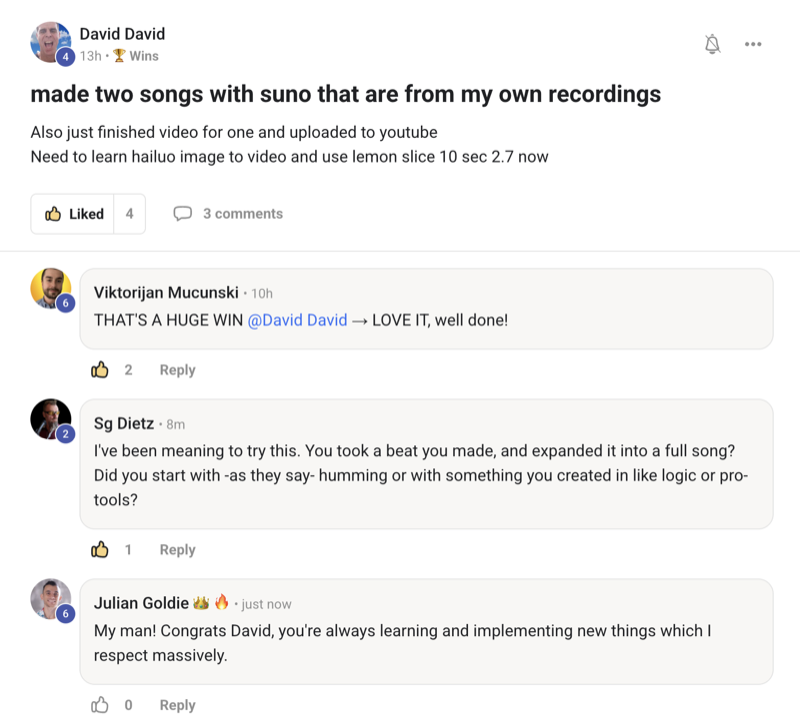
The Kimi 2.6 benchmark results just dropped and Kimi K2.6 is outperforming Claude Opus 4.6 and GPT 5.4 on multiple tests. That's a meaningful release for an open-source model, and after testing it across real workflows I've got a verdict on where it wins, where it loses, and whether you should switch.
This post covers where Kimi 2.6 wins on benchmarks, where it loses, what "outperforming Claude" actually means in practice, and whether you should add it to your stack.
The Headline Kimi 2.6 Benchmark Numbers
Kimi K2.6 is outperforming Claude Opus 4.6 on max effort tests, GPT 5.4 in Humanities Last Exam, and Gemini 3.1 Pro on benchmark tasks. Plus it's open source.
That's a meaningful release across all three competitive dimensions.
What Makes Kimi 2.6 Different
Three things stand out from the rest of the open-source field.
The first is that it's designed for agentic tasks rather than chat or pure code. Kimi K2.6 is built specifically for autonomous agent work — real long-horizon tasks where the AI plans, acts, validates, and iterates without constant babysitting. The second is genuinely impressive long-horizon coding. In demos, Kimi 2.6 downloaded and deployed a local AI model on a Mac autonomously, implemented optimisations, and did all of it without human prompting after the initial mission. This is the same long-horizon capability we're seeing from Z AI's GLM 5.1 and the broader goal-pursuing AI shift. The third is that it's open source — anyone can use Kimi K2.6 with no expensive licensing, which matters for indie operators and small businesses.
How To Test Kimi 2.6 Yourself
Free access lives at kimi.com with several modes available.
Agent mode handles single-agent autonomous work. Agent Swarm runs a team of agents working in parallel. Thinking mode is for reasoning-style chat. Instant mode is for fast responses. There's also a turbo speed mode for faster execution when you need it.
Pick the mode that matches the work you're doing.
🔥 Want my full Kimi 2.6 benchmark playbook? Inside the AI Profit Boardroom, I share my Kimi setup, comparison tests, and 30-day road map. Plus a 6-hour OpenClaw course (which works with Kimi via Kimi Claw) and weekly live coaching. 3,000+ members. → Get the playbook
Specific Kimi 2.6 Benchmark Wins
From the released numbers, Kimi 2.6 leads on max effort (beating Claude Opus 4.6), Humanities Last Exam (beating GPT 5.4), long-horizon coding (strong performance versus all major competitors), and coding-driven design (solid results on design benchmarks).
These aren't cherry-picked categories — they're exactly the kinds of tasks that matter for serious agentic work.
Specific Benchmarks Where Claude/GPT Still Win
Honest about where Kimi falls short.
For very complex single-shot reasoning, Claude and GPT still edge ahead. Specifically, top-tier reasoning on hard novel problems, very long context (100K+ tokens) handling, and some niche language tasks all still favour the established models.
For most everyday agentic work, though, Kimi 2.6 is competitive or better.
Real Use Cases I've Tested
Six specific things I've run on Kimi K2.6 to validate the benchmarks against real work.
The first was building a website from a prompt. I fed it copy from my AI Profit Boardroom and asked for "a beautiful fun website for this." The output had clean design, working buttons, and a full preview — pretty good for a one-shot generation.
The second was building an OS-style desktop environment. The demo where Kimi swarm built a full Linux-style desktop from scratch genuinely worked, with a real working file browser, terminal, text editor, and games. That's autonomous capability of a different order from previous releases.
The third was a job matching system. The demo built a full job matching app with an application tracker included, all files generated and ready to deploy. The fourth was spreadsheet automation through Kimi Sheets, which lets you build database-style systems inside spreadsheets — useful for automating SMB workflows.
The fifth was deep research reports. Kimi's deep research mode pulls multiple studies and formats interactive reports. I've used it for SEO research and it's comparable to dedicated research tools. The sixth was Kimi Claw, a cloud-hosted version of OpenClaw with one-click setup, scheduled tasks 24/7, and phone management. I cover OpenClaw broadly in OpenClaw Computer Use — Kimi Claw is an alternative hosting model.
Five Methods For Using Kimi 2.6
Quick reference for picking the right mode.
Kimi Agent Swarms is for big tasks with multi-agent execution. Kimi Agent is for single tasks with smaller scope. Kimi Chat (thinking plus instant) is for quick lookups. Kimi Claw is the cloud-hosted OpenClaw with Kimi as the model. Kimi Code is the CLI alternative similar to Claude Code.
For each task, pick the right mode rather than defaulting to one.
Kimi Code Vs Claude Code
Side-by-side comparison of the two CLI options.
Kimi Code is cheaper, gives you more usage at the same price tier, and is solid for routine coding. Claude Code has top-tier reasoning, handles edge cases better, and has a more polished UX.
For raw power, Claude Code wins. For value, Kimi Code is competitive. I use both depending on the task.
The Time-Saving Reality
McKinsey research suggests AI agents can save 60-70% of daily time. For Kimi 2.6 specifically, I've seen 90% time saving on content briefs, 80% time saving on research, and 70% time saving on code prototypes.
These are real numbers from real work, not hype.
Custom Skills In Kimi
Kimi supports custom skills, so you can train it to be expert at specific domains. The pattern is simple — create an "SEO" skill, use that skill every time you create a blog post, and Kimi generates content plus publishes it.
Skills compound. The more you use them, the more useful they become.
What's Next For Kimi
Predictions based on the current trajectory.
Continued benchmark improvements are likely as the team iterates. Better tool integration is coming based on roadmap signals. More domain-specific skills will land as the community contributes them. Possibly a closed-source enterprise tier alongside the open-source community version, following the pattern other open-source AI projects have used.
For now, the open-source release is the most exciting thing in agentic AI.
🚀 Want my full Kimi + agent stack? The AI Profit Boardroom has my Kimi setup, OpenClaw 6-hour course (works with Kimi Claw), 2-hour Hermes course, daily training, and weekly live coaching. 3,000+ members. → Join here
FAQ — Kimi 2.6 Benchmark
Is Kimi 2.6 really better than Claude Opus 4.6?
On specific benchmarks, yes. For all use cases, it depends on the task.
Is Kimi 2.6 free?
Free access at kimi.com. Paid tiers for higher usage.
Is it open source?
Yes — that's part of why it's notable.
Can I run Kimi locally?
Yes — via the open-source release.
Should I switch from Claude or GPT to Kimi?
For agentic work, give Kimi a serious test. For top-tier reasoning, keep Claude or GPT as backup.
How does Kimi Claw compare to OpenClaw?
Kimi Claw is cloud-hosted OpenClaw with Kimi 2.6 as the model. Easier setup, less customisation.
What's the best Kimi mode for SEO content?
Agent mode for short tasks. Agent Swarm for multi-post strategy work.
Related Reading
- Kimi K2.6 Agent Swarms — multi-agent walkthrough.
- OpenClaw Kimi K2.6 — OpenClaw + Kimi setup.
- Hermes Agent Swarm — Hermes-side multi-agent.
📺 Video notes + links to the tools 👉
🎥 Learn how I make these videos 👉
🆓 Get a FREE AI Course + Community + 1,000 AI Agents 👉
The Kimi 2.6 benchmark results show it's a serious contender — beating Claude Opus 4.6 and GPT 5.4 on key tests means it deserves a spot in your AI stack.